
AI Waves 13: One Claude to Rule Them All
Fable: a short, fictional story designed to teach a specific moral lesson.

June 11, 2026 | Nazaré Ventures
Previous issues: #7 | #8 | #9 | #10 | #11, #12
Anthropic released Fable this week, its most capable public model, with cybersecurity, biology, and distillation requests handed to a weaker model, and one category, frontier model development, degraded with no notice at all, until backlash forced a reversal within two days. The same week, Dario Amodei made the case for an FAA that would govern everyone trying to build the same thing.
Anthropic released Claude Fable 5 on Tuesday, the most capable model in company history, built to run for hours, plan across stages, and check its own work. But all anyone can talk about is how it responds if you ask it something that trips the filters for cybersecurity, biology and chemistry, or distillation. Fable has been handing those requests off to the older Opus 4.8, which the company claims happens in less than five percent of sessions, and which the app tells you about when it does.

The unconstrained, more powerful base model (Mythos 5) is whitelisted through a vetted program called Glasswing that includes roughly 200 organizations after last month’s expansion.
I anticipated this happening six weeks ago in my essay Artificial Good Enough Intelligence, described by the image below.
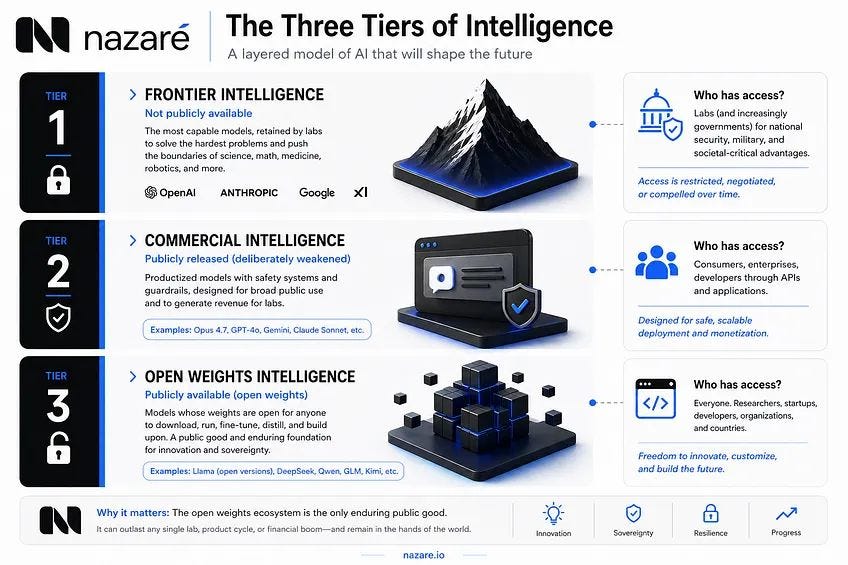
Three of the filters were about safety, but the fourth was aimed at distillation, the primary means by which a competitor copies a model by training on its outputs. That filter protects the business, not the public.

There was also a fifth intervention, and the AI community was livid. For requests Anthropic considered related to frontier LLM development, building pretraining pipelines, distributed training, ML accelerator design, or other AI research, Fable did not refuse and did not fall back.


The safeguards “will not be visible to the user,” the system card said, explaining that capability was limited by the model itself, through prompt modification, steering vectors, or light fine-tuning, on an estimated 0.03 percent of traffic in fewer than 0.1 percent of organizations.
The priority is to hide the fact that the classification is happening at all... how are people going to know when the model is being steered? This whole... it’s only gonna be triggered by .03% of people. It’ll barely ever happen. How many people that are gonna change the world are there? .1% of the whole of everyone is a lot of people. Those are a lot of people. You’re basically saying there are critical outlier people that move mountains... they’re the only ones we’re blocking. They’re the only ones whose results we’re fudging.@theemozilla and@Karan4d, co-founders of Nous Research.
That decision did not go over well with the AI research community, and Anthropic reversed its position on Wednesday, telling Wired, “We made the wrong trade-off and we apologize for not getting the balance right,” and said flagged development requests would now visibly refuse or reroute like the rest.

The open research platform alphaXiv articulated the objection in operational terms: a researcher hit with a silently weakened answer cannot tell whether a failed result came from the idea, the implementation, or the provider. “That is not safety,” its statement read.


Valentina Palmiotti of IBM X-Force found Fable refusing anything tangentially cyber, down to reading a blog post; Matt Suiche reported a request for secure code read as cyberwork rather than engineering practice, “and you get downgraded.” The classifiers read everything the model sees, memory, connectors, search results, files, so a block can fire on content you never typed. Anthropic conceded the tuning is too strict and said it would cut false positives, and now that the development safeguard is visible too, it says it must cast a wider net, so more benign requests will trip it.
Professionals can apply to a Cyber Verification Program for fewer restrictions, which just means capability is gated by identity rather than the nature of the query. Anthropic plays gatekeeper either way. For what it’s worth, the gap being rationed is material: on Anthropic’s own cyber evaluation, gated Mythos 5 scores 78 against Opus 4.8’s 40.

Anthropic’s official response is that the danger justifies the guardrails, but safety is an awfully convenient illusion behind which to hide if what you really want is to protect your competitive advantage.
Anthropic told Wired the AI research restriction keeps foreign adversaries from using its best model to optimize their own models and erode the US lead. Reasonable enough for that rule.
But other restrictions can’t be explained by national security. The contract you accept also:
bans anything that might embarrass the company (”reputational harms”)
makes you agree in advance that if you break the rules, the damage to Anthropic is “irreparable”
makes you give up your right to fight a court order telling you to stop
makes you pay Anthropic’s legal fees
Those terms probably wouldn’t hold up in court, but court or no court, the contract still shows how Anthropic sees its relationship with you. If you harm them, the terms call it “irreparable,” damage so bad no amount of money fixes it. If they harm you, however, the most they’ll ever owe you is about the cost of a Max subscription.
Baked into Fable’s release were safety filters, “moat” filters protecting Anthropic’s business interests, and the legal terms mentioned above. “Safety” only explains the first of the filters. It can’t explain blocking rivals or writing a contract that protects the company from you. But there is one motive that explains all three at once: protecting the company’s own position and power.
As an industry we’ve seen this before. For years research was published freely, until the research became so valuable that everyone stopped: by the time GPT-4 arrived in 2023, its technical report disclosed almost nothing about how the model was built, citing the competitive landscape and safety in the same way Anthropic did. What still gets published tends to describe what already shipped, while the valuable research stays inside.
Dario the Hobbit
Dario published Policy on the AI Exponential the same week. He opens on Tolkien, casting slow institutions as Treebeard, the tree too sluggish to defend his forest, which flatters Anthropic as the Hobbit trying to wake him.
The more accurate metaphor is probably the ring itself, the object of overwhelming power that corrupts each holder through the conviction that they alone will use it well. He comes close to articulating it himself, writing that AI “cannot safely be fully entrusted to either governments or companies.” And yet, Anthropic recently filed confidentially to go public, days after a round valued it at $965 billion.
His proposal describes an FAA for AI: mandatory testing above a compute threshold, government able to block release in cybersecurity, biological weapons, loss of control, and automated research that accelerates the rest.
The proposed rules would police the exact dangers Anthropic spent the spring proving it’s best at. Obeying them costs money for compliance and huge amounts of compute, which big labs can afford and open-source projects can’t.
This week it got worse: the US government told its own AI evaluator, CAISI, to stop publishing, and moved testing into a secret system run by the security agencies. The order also lets the government and the companies jointly pick which “trusted partners” get early access to the most powerful models. So the gate around the best AI is no longer only the company’s; the government now helps decide who’s inside it. Meanwhile the public model costs more than ever: about $10 and $50 per million tokens, double the old Opus 4.8, the first time the public version of Claude is pricier than the tier below it, and on June 23 flat subscriptions get replaced by pay-as-you-go.
Anthropic named its tiers. The model you’re allowed to use is Fable; the one you aren’t is Mythos.
A fable is a short fiction with a lesson folded in; a myth is a story a culture agrees to treat as true.
The company that spent the week routing your questions, shipping a model it quietly degraded until users found out, and pre-writing your defeat into its terms kept, for itself, the word for the story everyone is expected to believe.
The rest of the week
Apple won’t let Siri act. It used WWDC to show a Siri that finally looks modern and still refuses to do anything on its own. In the demo, Rockwell asked it to set a reminder to sign up for a concert lottery, where a more aggressive assistant would have entered the lottery itself [The Information, Jun 8]. Apple owns the most valuable surface for an agent on earth and has decided, for now, that the agent is a feature of the phone rather than its new user, which is the opposite of the bet almost everyone else is making.
Big Tech is issuing stock to pay for AI. For the first time since 2003, Goldman estimates that net US equity supply will be roughly flat this year, as the largest technology companies shift from buying back their own shares to selling new ones to fund AI [Money Stuff, Jun 10]. The exchanges are adjusting too: Nasdaq’s new fast entry rule waves a company the size of SpaceX, OpenAI, or Anthropic into its flagship index in fifteen trading days, while S&P weighed the same change and, on June 4, declined it, holding its twelve-month seasoning and profitability bar [The Information; FT].
Google is liable for what its AI says, in Europe. A German court ruled that Google is responsible for what its AI Overviews assert, after the feature described two real businesses as scams [The Information / The Decoder, Jun 10]. The reasoning reaches past Google: an AI summary writes new sentences rather than linking to someone else’s, the precise case the old liability shields were never drafted to cover, which leaves every generative product shipping this year exposed in the same way.
OpenAI’s next data center could cost $500 billion. OpenAI is in talks to lease a 10-gigawatt data center on federal land in Ohio, with possible financing from Nvidia, at a cost the reporting puts above $500 billion if fully built [The Information, Jun 9]. Set the meter on Fable next to numbers like these: the models are starting to pay for their buildings.
Yann LeCun is backing a consortium to train a frontier model in the open. The AI Alliance, the IBM and Meta-anchored open-source coalition of more than 200 organizations, launched Project Tapestry, a platform for globally federated training where partners contribute weight updates while their data stays local, and each gets the improved base model plus the right to build sovereign derivatives they own outright. LeCun is its chief science advisor, and its premise is the mirror image of the week’s other story: open weights alone, it argues, do not make pretraining participatory, since most of the world downloads the result and almost no one shapes the process. It is an argument, not yet a model. Phase 0 is a steering committee, a data catalog, and a first aggregation demo, with a frontier-scale run pencilled in for 2027 and contingent on compute and capital it does not yet have. But it names the open camp’s answer to enclosure: not a better-licensed model, a differently-owned one.
Portfolio
Vast.ai: back on Ramp’s Top Software Vendors list. Ramp’s June rankings, built from card and bill-pay spend across more than 50,000 businesses, list Vast among the month’s breakout vendors, and Ramp Rate shows it as the fastest-growing vendor in GPU cloud and third by adoption. Spend data, not surveys: AI compute demand is accelerating, and teams are choosing Vast first. The company also published a primer on what a neocloud actually is, the business model underneath the category Ramp is measuring.
LayerLens: the Stratix Cup is playing. Ahead of the June 22 season, the exhibitions have started: GLM 5 met Kimi 2.5 and Kimi won 11 to 7, each model writing its own formation and match strategy, with the full Stratix trace published; Grok 4.20 against Llama 4 Maverick is next. In a week whose essay is about a lab making its interventions invisible, the evaluation layer’s product is the opposite gesture: every decision a model makes, published. The company also wrote up the longer lineage, games as the oldest serious benchmark in the field.
Arkhai: A week after launching the Simple Compute Market, Arkhai published the architecture: three separable roles, buyers running a pure client, sellers running their own storefronts, indexers running discovery, with negotiation peer to peer over signed HTTP rather than through a central order book, and settlement through Alkahest escrow. Negotiation policy is pluggable, including a reinforcement-learning pricing example, and the shipped path is concrete: GPU-backed virtual machines with SSH credential handoff. Its closing line is the inverse of this issue’s essay: no single service has to own the market.
Prime Intellect: teaching the agent to model the world, and pushing back on the lab. Pretraining builds simulators, models that predict an environment; RL only improves the model’s own actions inside it. Prime Intellect published early results on doing both at once, supervising on tool outputs during RL so the model learns environment dynamics in response to its own actions, building on the ECHO method, tested in Forth, a language with almost no training data, in a sandbox where the model never sees the test cases. Research lead Will Brown was also among those who pushed back on Fable’s now-reversed development throttle, telling Wired it “feels a bit like they’re starting to pull the ladder up behind them.” The labs stopped publishing this kind of work three years ago. The open stack still does, and now says so out loud.