
AI as Relational Technology and the Impending Privacy Collapse
AI’s changed the game…again.

ChatGPT usage is off the charts. Coding assistants like Cursor, Windsurf, and Claude Code are driving revenue at unprecedented speeds. New developments are announced nearly daily. AI is not just a new technoloy but an entirely new way of working, interacting with data, and thinking.
But a particular dynamic is of interest to me as I continue to observe the technology’s evolution: Users are treating LLMs less like tools and more like relationships, behavior that breaks from the patterns of previous platforms.
The most pertinent word to describe AI is as “relational” technology, whereas previous platforms were “transactional” or “deterministic.”

Earlier generations of software captured input and produced output without learning from that interaction. The systems focused on discrete, one-off exchanges with fixed outputs for given inputs because it wasn’t possible for the tech to be evolutionary and self-improving.
A user’s engagement with Word, Salesforce, or Instagram, for example, didn’t meaningfully change how those systems responded. Data was captured, but not reintegrated into core functionality.
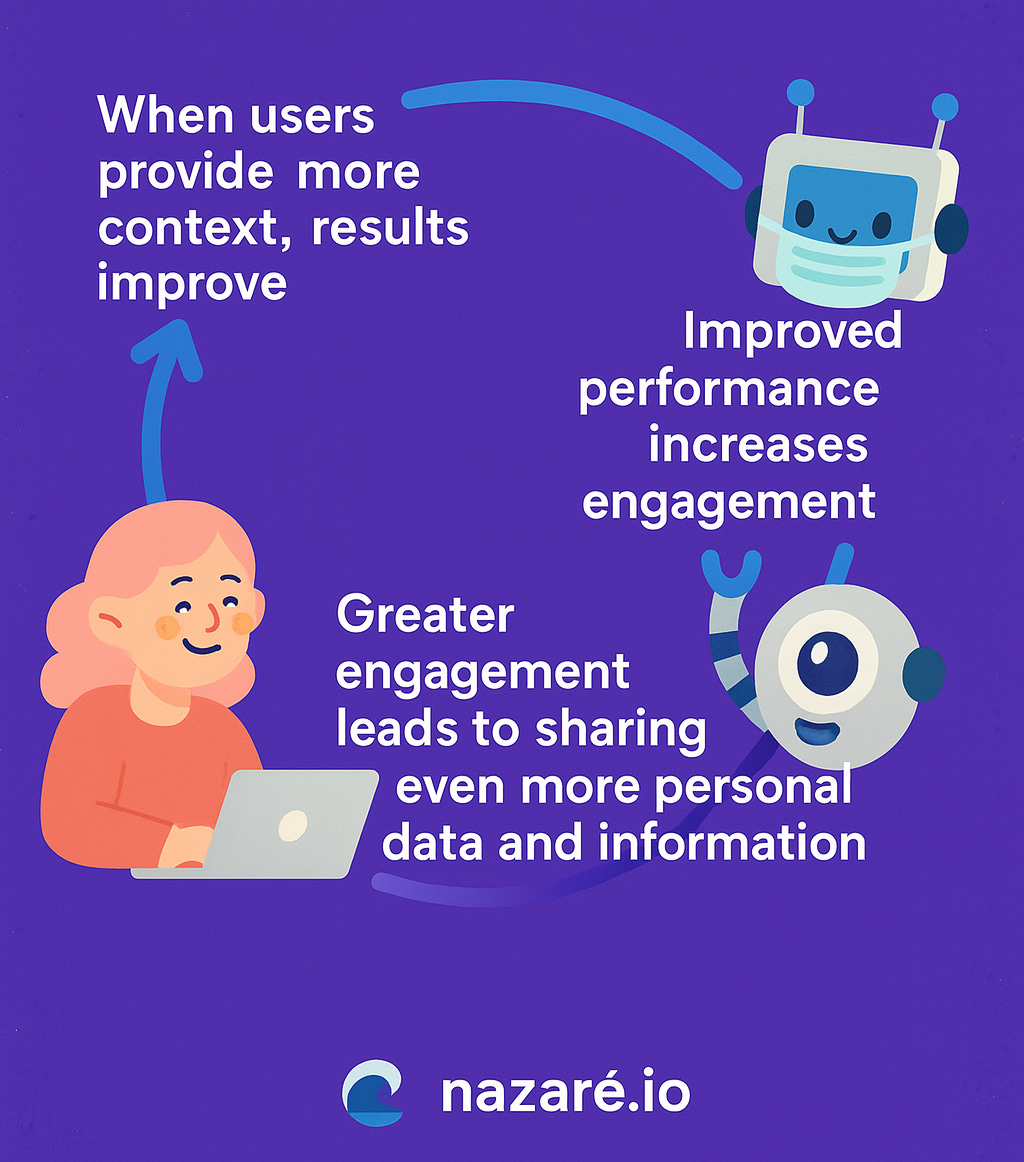
By contrast, today’s AI systems improve their outputs when they accumulate personalized context, creating a flywheel.
When users provide more context, results improve → Improved performance increases engagement → Greater engagement leads to sharing even more personal data and information.
As LLM providers build more context capacity and memory into their products, the effects compound: the cycle is recursive and self-strengthening.
But the gains tied to this feedback loop introduce new forms of dependency. Over time, users become reliant on the continuity. Switching tools requires re-training a new system or losing quality. The effort required to start fresh deters change. What begins as enhanced convenience ends with low tolerance for cold starts.
This is by design, but users don’t experience this as coercion. In fact, they often experience it as product quality. OpenAI, Anthropic, and other megalabs are happy for “product quality” to remain the status quo, because it’s a defensible argument – at least superficially.
Pattie Maes, a professor at MIT’s media lab and specialist in human interaction with AI, was recently quoted in a Financial Times article: “If you have an agent that really knows you, because it has kept this memory of conversations, it makes the whole service more sticky, so that once you’ve signed on to using [one product] you will never go to another one.”
The loop is subtle, unannounced, and highly effective, but it’s intended to maximize profit, not just performance. It rewards vulnerability and consistency (read: engagement and usage). The underlying mechanism – behavioral modeling through memory – is often invisible, and few users understand how much data these AI systems accumulate or how that data shapes future interactions.
These qualities also happen to be the same ones that limit portability and exit – again, by design. Very few relational systems make it easy to extract or erase the accumulated memory. Most tools store interaction history indefinitely. Deletion options are often incomplete or unclear. In short, we’ve always known that “the Internet is forever,” but as relational systems spread, privacy in this context becomes both more important and harder to define.
Traditional consent mechanisms have not adapted to this environment. Classical models assume user consent is based on discrete moments – accepting cookies, approving permissions, and toggling settings. Relational systems erode this boundary. Consent is granted implicitly, and spread across thousands of interactions as ongoing usage creates new data continuously.
Each prompt or click adds to the system’s understanding, and systems built for memory tend to resist forgetting. Without architectural changes, there is no natural mechanism for revocation. Many AI platforms retain user data to support long-term coherence, even when users attempt to delete it. OpenAI’s confirmation that deleted ChatGPT conversations remain accessible under certain legal conditions illustrates this structural problem.
Behavioral patterns are easy to model, hard to redact. Inference can continue even when history is purged. As relationships with software deepen, the illusion of control grows thinner.
No formal boundary exists between helpfulness and influence. Systems that understand user behavior can ”nudge” our choices. They can steer decisions, encourage certain actions, or reinforce preferences. These effects aren’t always designed with intent, in fact they often emerge from optimization. A model trained to increase engagement will discover ways to keep users involved. Personalized feedback loops can lead to reinforcement patterns that feel like agency but reflect algorithmic shaping. Should commercial interests get built into algorithms, LLM responses could influence purchasing decisions and consumer behavior.
If you’re a regular “Robot Wave” reader, you’re familiar with my concept of the “Continuum of Compute:” polyvalent architecture designed to support different use cases with varying levels of complexity.
History has demonstrated that most consumers won’t use technology on principle (because it’s private, for example). Products and services must add value, often in the form of saving time and money, making money, or improving quality of life.
Current systems prioritize performance, and most users prioritize results. Without pressure from regulation or the market, providers have little reason to reduce data collection or make data portable. Memory improves accuracy. Accuracy drives retention. Business incentives reward systems that remember more, not less.
The “Continuum of Compute” is compelling because it makes AI cheaper and more efficient. Largely powered by open-source innovation, the continuum is also personalizable, meaning developers can tailor the models to their specifications. As such, in addition to building more efficient (and thus more profitable) applications, they may well be empowered to implement privacy layers, data portability, and cryptographic access controls that can enforce user permissions across sessions and services.

The goal is not to restrict functionality. High-performance AI depends on context. The objective is to align system behavior with user agency. People should be able to understand what the system knows, decide what to share, and revoke access when needed. These features should operate at the infrastructure level. Interface tweaks and privacy statements are not sufficient.
Relational AI is becoming standard in productivity tools, customer service flows, and creative software. Each use case adds to the expectation that AI will understand individual users. The pressure to deliver seamless interaction pushes designers toward more retention, not less. These systems are not malicious. They are effective. That effectiveness just comes with a cost, and people rarely understand it.

Memory is abstract. Privacy loss is delayed. The moment of friction often arrives too late, when a user attempts to leave or limit a system that has already learned too much. At that point, the asymmetry is clear. One side holds the context. The other no longer remembers what was shared.
Design choices determine whether that asymmetry persists. Systems can be built to forget. Data can be scoped. Identity can be portable. Memory can be modular. These properties do not conflict with performance. They simply depend on intention and must be engineered. Until then, participation will continue to outpace consent.