
The Labor Market for Compute
When agents become the customer, the moat goes to whoever they trust

In 2002 I was running research at Sun Microsystems focused on archival storage built on clusters of cheap AMD servers, and Sun’s salesforce hated it. Sun made its money selling $40,000 UNIX boxes, but my prototype, which Sun eventually shipped as the Sun StorageTek 5800, ran on $1,500 boxes from Dell. Internally, the argument was that customers paid a premium for reliability and that commodity hardware couldn’t deliver. The market thought otherwise, and by 2009 the company had lost 98% of its market cap and agreed to be acquired by Oracle.
I keep returning to Sun because the pattern repeats: monolithic providers come apart once cheap, commodity supply emerges beneath them. Commodity supply usually starts out fragmented, and markets emerge to coordinate buying and selling. But sometimes commodification creates a new substrate altogether, one that attracts a new kind of customer with new demands. When that happens, value migrates from the monolith to whoever best serves the new customer, which means not only coordinating fragmented supply, but verifying it and tailoring it.
This is happening to compute right now.
Models get all the attention, often for good reason. But capable models created agents, and it has quickly become clear that agents are an entirely new class of consumer for compute that warrants tailor-made infrastructure to support their needs.

Work as Compute
As we wrote in April: “AI has collapsed [information] technology and its user into a single, powerful, semi-autonomous feedback loop, a tool that wields its own tools, does its own work, and has the capacity to operate on its own.”
Work has always been something humans do. Work is now a thing agents can do on their own by consuming compute. Consequently, as agents take on more economically valuable work, the substrate of work shifts from human labor and intelligence to compute itself. Navigating that shift means solving for how best to provision compute for agents. Nothing built for human procurement fits how they consume.
For two decades, compute was sold to humans buying long-term capacity with long lead times, and pricing was based on reserved capacity. Agent compute, by contrast, is liquid: produced, distributed, and consumed in real time by always-on, programmatic users who don’t resemble humans. Agents need contracts they can read, price, and walk away from.
All of this also needs to be possible across a heterogeneous supply of compute, because the compute serving the agent ecosystem will come from datacenters, neoclouds, commercial surplus, long-tail independent operators, and providers around the world offering a diverse set of assets that move between these categories over their lifecycles.
In the same agent essay I wrote: “The instinct is to frame [compute provision] as client-server done differently. It is not. [Agents have] a different relationship to the software, and [they] produce different requirements at every layer.”
The whole apparatus is reorganizing, and a multi-layered labor market is emerging to accommodate agents and their demands.
Employee, Not Commodity
One way to approach the situation is to treat compute as a simple commodity. Compute has a commodity-flavored dimension that can support exchanges and financial instruments like futures contracts: reserved capacity, GPU-seconds, spot pricing, and so on.
At the Milken Institute Global Conference in early May, BlackRock CEO Larry Fink told the audience: “A new asset class will be buying futures of compute.”
But futures exist largely to hedge price risk for known, interchangeable goods over time. (In most cases, traders don’t even accept delivery of the actual underlying commodity.) Compute, however, isn’t fungible at the bare metal: no two units of compute are interchangeable.
For one thing, tasks vary in what compute they need, and even for the same task, hardware varies in speed, cost, power profile, and sometimes output quality. An H100 produces a different number of useful operations per dollar than an MI300X, and these differences persist across all available silicon. Treating compute as fungible is like treating engineers as fungible: true at the org chart level, false everywhere else.
As we’ve argued before, not every task requires frontier intelligence, and mismatching a task to the optimal compute required to perform it gets expensive at scale, wasting time and money or sacrificing quality. Conversely, properly matching tasks to their optimal compute creates enormous value at scale over time.
The same hardware can perform differently depending on the host. Two providers running identical silicon can vary in uptime, reliability, throughput, and billing accuracy.
Agents purchasing compute to perform work are thus doing more than managing their price exposure to a critical resource. Instead, they’re looking to purchase the right compute that fits their selection requirements at the right moment to complete their task. In that sense, the compute agents seek isn’t a commodity at all, and agents buying compute is more like hiring an employee than trading a futures contract.
Where the Hiring Happens
Compute is usually treated like a single market, with NVIDIA dominating the base layer (AMD, Intel, and others pick up the pieces) and the frontier labs sitting on top.
So where does an agent go to hire compute? Where in the stack does this agent labor market exist?
I see four layers emerging in the compute stack: Silicon, Provisioning, Models, and Orchestration.
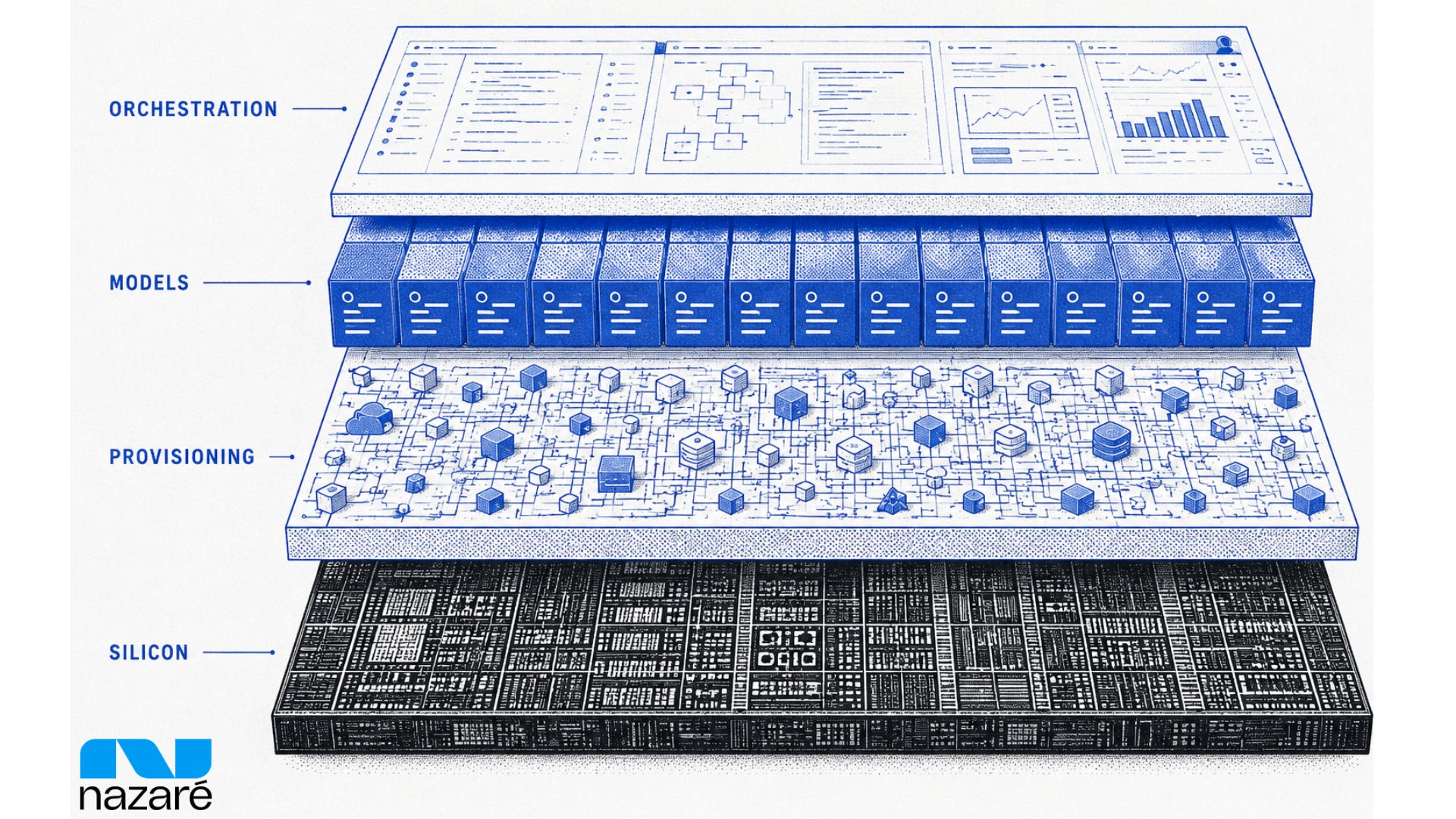
Silicon and Models are self-explanatory. Orchestration is the layer I argued holds durable value in Models Aren’t Moats: when models themselves commoditize, the value migrates to whoever specializes their otherwise “general” intelligence.
Agents will hire compute in the layer called provisioning, where heterogeneous silicon gets assembled and packaged as a liquid resource specifically tailored for agents to consume.
Provisioning is the process of matching a workload to a host that has the compute, pricing it, metering it, and releasing it when the job ends. Superficially, it sounds like the next great programmable-infrastructure business akin to what Twilio does for telecom, Stripe for payments, Vercel for deployment, and Cloudflare for the network.
Each of these businesses took fragmented, unruly supply and wrapped it in a single clean API, providing a reliable, boring-but-critical service everyone configures once and then forgets about. Provisioning can read like a similar kind of business, but there’s one nuance: verification.
Those companies could easily verify what they brokered. Compute provisioners coordinate a resource whose quality they can’t directly verify. They have no way to inspect every machine, and they haven’t met every host. The listing is a claim, not a guarantee.
Can I Trust This Candidate to Do the Job?
Every hire ultimately turns on two questions:
Is the candidate who they claim? (Identity)
Will they do what they promise? (Performance / Quality)
Hardware identity (is an H100 an H100?) is solvable, and is the easier of the two questions to answer. Cryptographic attestation can prove a GPU is the make and model it claims to be, with the memory and location it advertises. Trusted execution environments (TEEs), NVIDIA’s Confidential Computing on Hopper and Blackwell, and AMD’s SEV-SNP on the CPU side are all production-grade examples available today.
But those services are like warranties: they cover only the chips they were built for. For older silicon, consumer cards, or the long-tail, heterogeneous inventory a compute provisioner carries, no such attestations exist, and zero-knowledge proofs of GPU work remain mostly research, with early commercial systems narrow in scope and not yet generalized.
And even these production-grade attestations aren’t static guarantees: ETH Zurich researchers disclosed a critical bypass against AMD’s SEV-SNP in April 2026, requiring an emergency firmware update.
Verifying quality and performance, on the other hand, is more difficult.
A host that passes an identity check can still throttle its GPUs, lower performance when the network is saturated, accept your business but run a second customer’s job on the same card while yours waits, or relist at a higher price the moment demand spikes. In short, hardware verification doesn’t prevent adversarial behavior and performance verification depends on trust earned over time.
The Long Watch
Reliability, like its opposite, is a pattern, not a property. Performance verification is a trust game won slowly, and the only way to predict it accurately is sustained measurement at scale.
The hard problem isn't catastrophic failure; that shows up immediately. The hard problem is drift. A clean six-month record can slope into oversubscription, throttling, or bandwidth degradation by month seven, and only the platform that’s been counting catches the slope before the customer does.
Compute provisioning is a learning machine. The platform starts cold, knowing nothing about its participants, and only improves by running transactions and watching them resolve until its model of the market converges. Each transaction adds a data point, but the value compounds as the database grows (and stays current).
As we mentioned, agent compute is liquid. Liquidity tied to verification produces tighter pricing, fewer failed jobs, and stronger matching. Those outcomes draw more buyers, who in turn draw more sellers, and a fuller marketplace throws off richer data, which feeds back into the system.
The provisioner with the best data ends up knowing its inventory the way a good headhunter knows its candidates, and that kind of verification is what makes compute provisioning valuable, especially for agents.
The edge accrues only through time, which is what makes it hard to copy. Capital can compress this advantage at the margin, either by running parallel measurement at scale or by acquiring a smaller provisioner with operational history. But the lead is durable because the system never stops running, and the operator with both the longest history and the freshest data keeps extending it.
The agent economy expands the problem in the provisioner’s favor. Most agent workloads aren’t latency-critical, so they run on hardware you’d never put an interactive user on: older cards, distant nodes, consumer silicon. Lower precision is fine for much of it, so int8 and int4 quantization bring smaller, cheaper chips into play. And the shortest, stateless calls can be packed into ephemeral scraps of capacity, the idle minutes between training runs no one bothered renting before.
Each of these opens a new slice of supply, and every one is more varied than the last. A broader, stranger fleet means more to verify, and the verification burden grows faster than the fleet itself. Eventually it outruns the tools built to handle it, and the operator who’s been measuring longest pulls further ahead.
The Pattern Repeats
Every labor market eventually centralizes around whoever has the best matching algorithm. The good headhunters and the staffing agencies that know their candidates win repeat business because they know which ones do which jobs well, can predict how they’ll perform under different conditions, and have earned the trust of both sides through years of decent matches.
Compute provisioning works the same way. The platform with the longest record of watching its hosts is the platform that agents will return to. The workers happen to be software and the buyers happen to be autonomous, but the market underneath is one we already know how to recognize.
The obvious counterargument is that hyperscalers will absorb this themselves, or that NVIDIA will pull provisioning into the silicon stack. They will try. But their inventory is captive and largely homogeneous, which is the opposite of what an agent labor market needs. Provisioning exists to coordinate a long tail of heterogeneous supply that hyperscalers can’t or won’t carry, with verification earned on hardware they don’t own. The agent economy will route around them the same way the cloud routed around enterprise IT.
That’s why I keep returning to my time at Sun. The buyers were already moving in 2002 when most of us couldn’t see it yet, and the value migrated to whoever built the cloud underneath. The buyers this time are agents and the commodity is heterogeneous compute, but the shape is the same.
The Symmetric Case
I’m an advisor and seed investor in Vast.ai, which has been doing this work for years across a long tail of independent hosts. Models Aren’t Moats made the case for durable value at the harness layer above the model, in Orchestration. This piece makes the symmetric case below, in Provisioning. Silicon and Models will keep commoditizing in the middle; the value that lasts sits at the two layers that translate between them and the buyer. The agent economy needs both, and the operators who win at either layer will be the ones with the longest record of doing the work.